hydroEDA Platform, main features.
Hydro Exploratory Data Analytics and Processing Platform
hydroEDA Platform reveals the hydrological underlying structure and model of data
Exploratory and confirmatory data analysis.
Data curation.
Resources can be built with external scripts and packages.
Data Analytics’s ecosystem enables growth and scale of operation and innovation through composing resources.
Building small and independent resources lowers members’s cognitive load.
Data mining, data analytics.
Knowledge is stored and shared.
Open for expansion. Extensible Framework.
Exploratory and confirmatory data analysis.
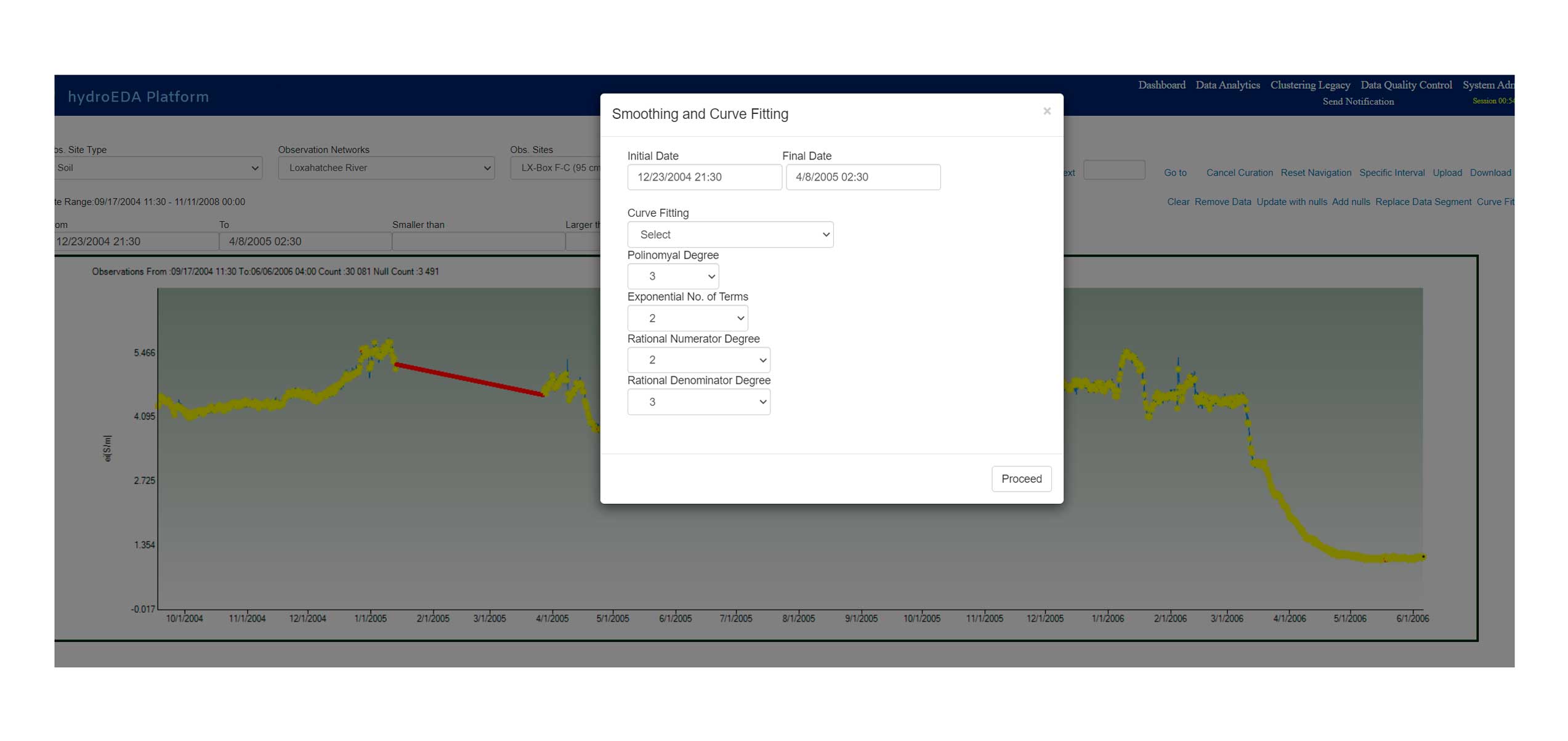
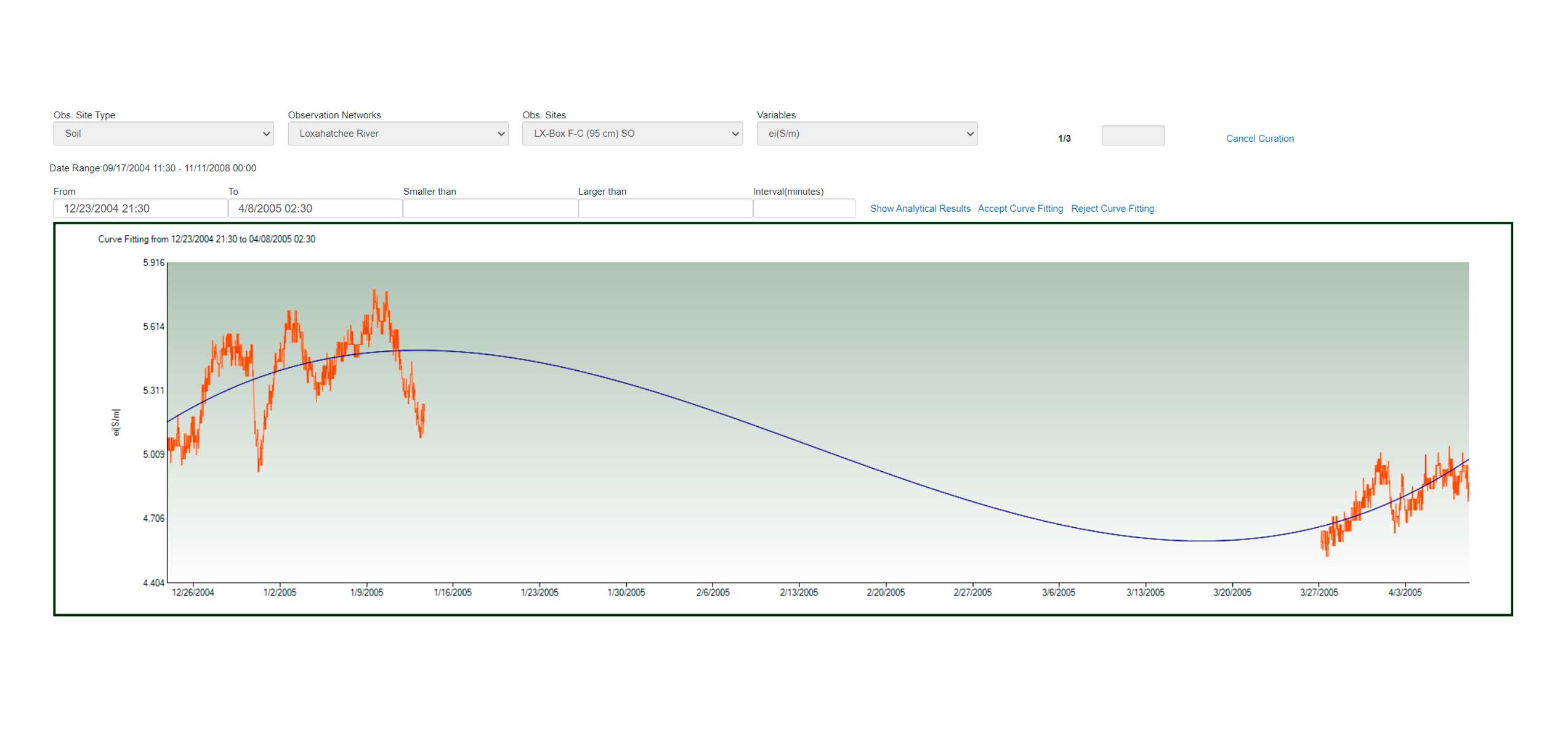
Smoothing Filtering
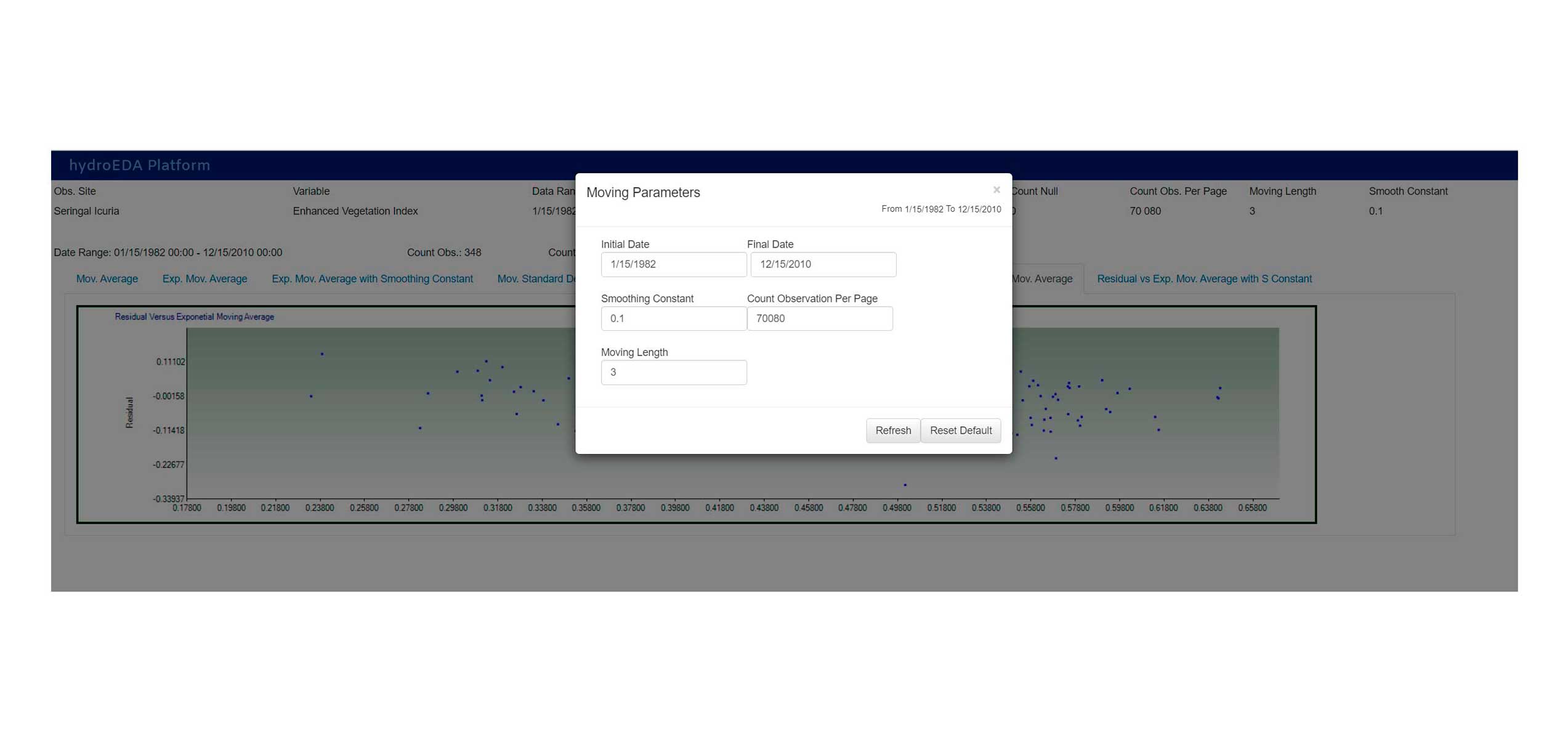
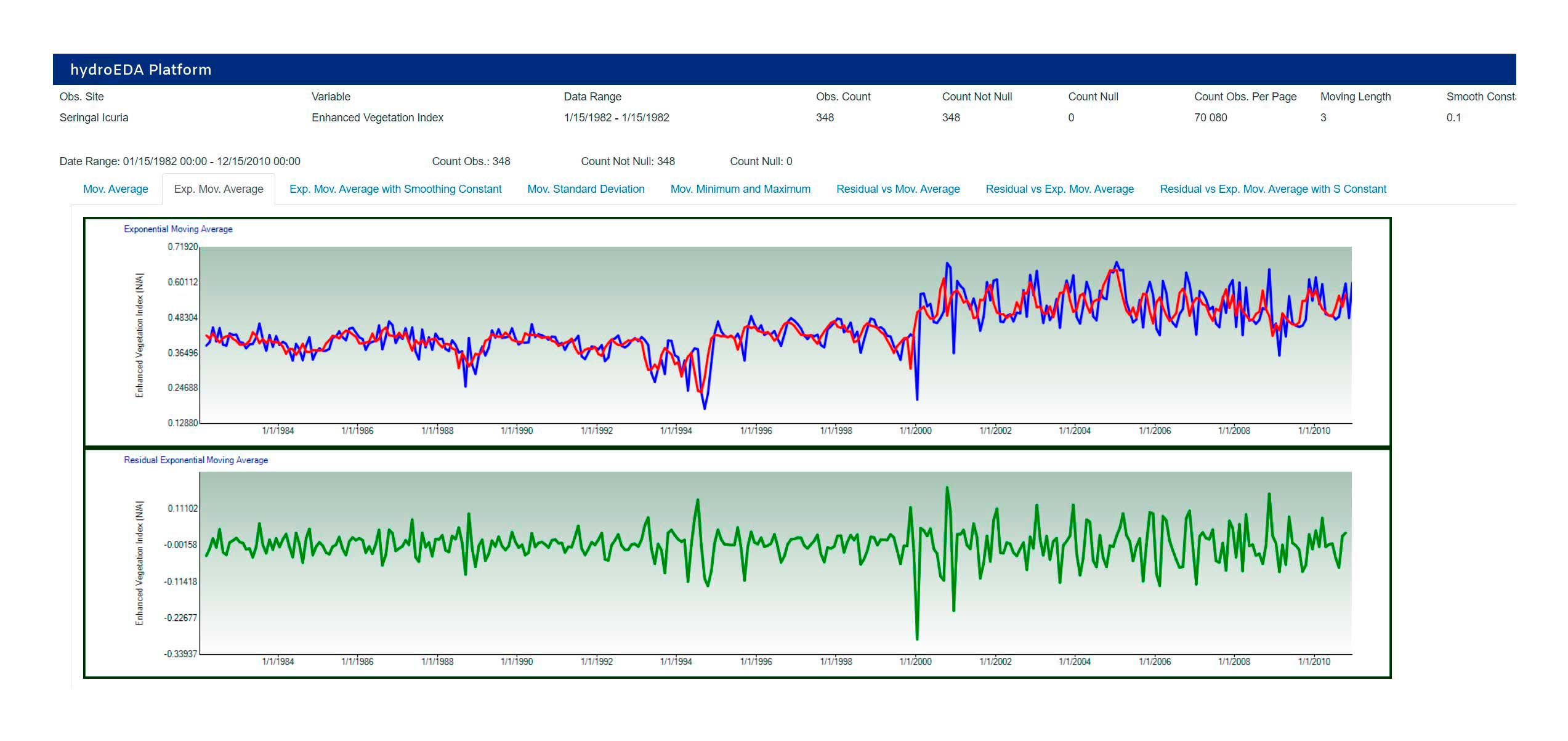
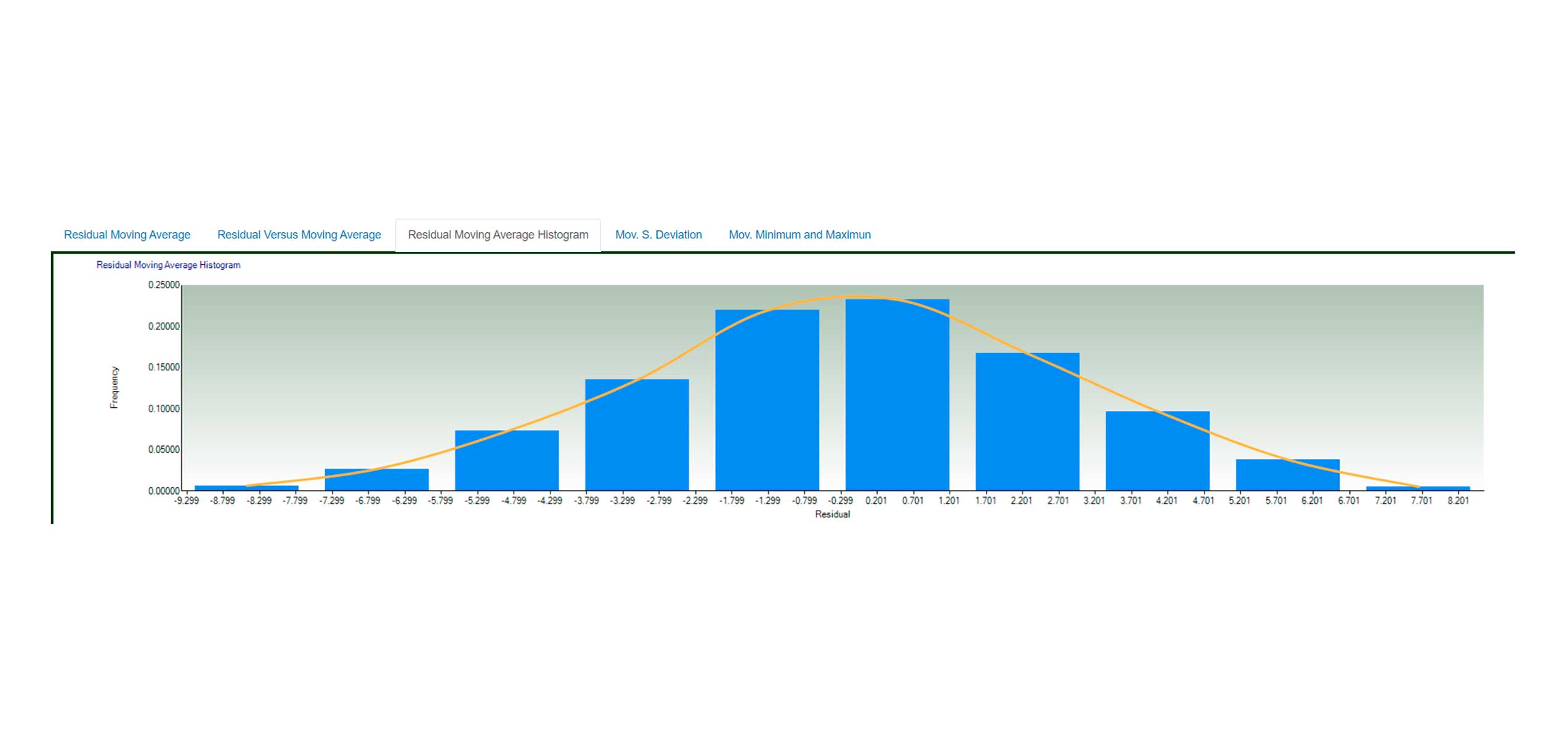
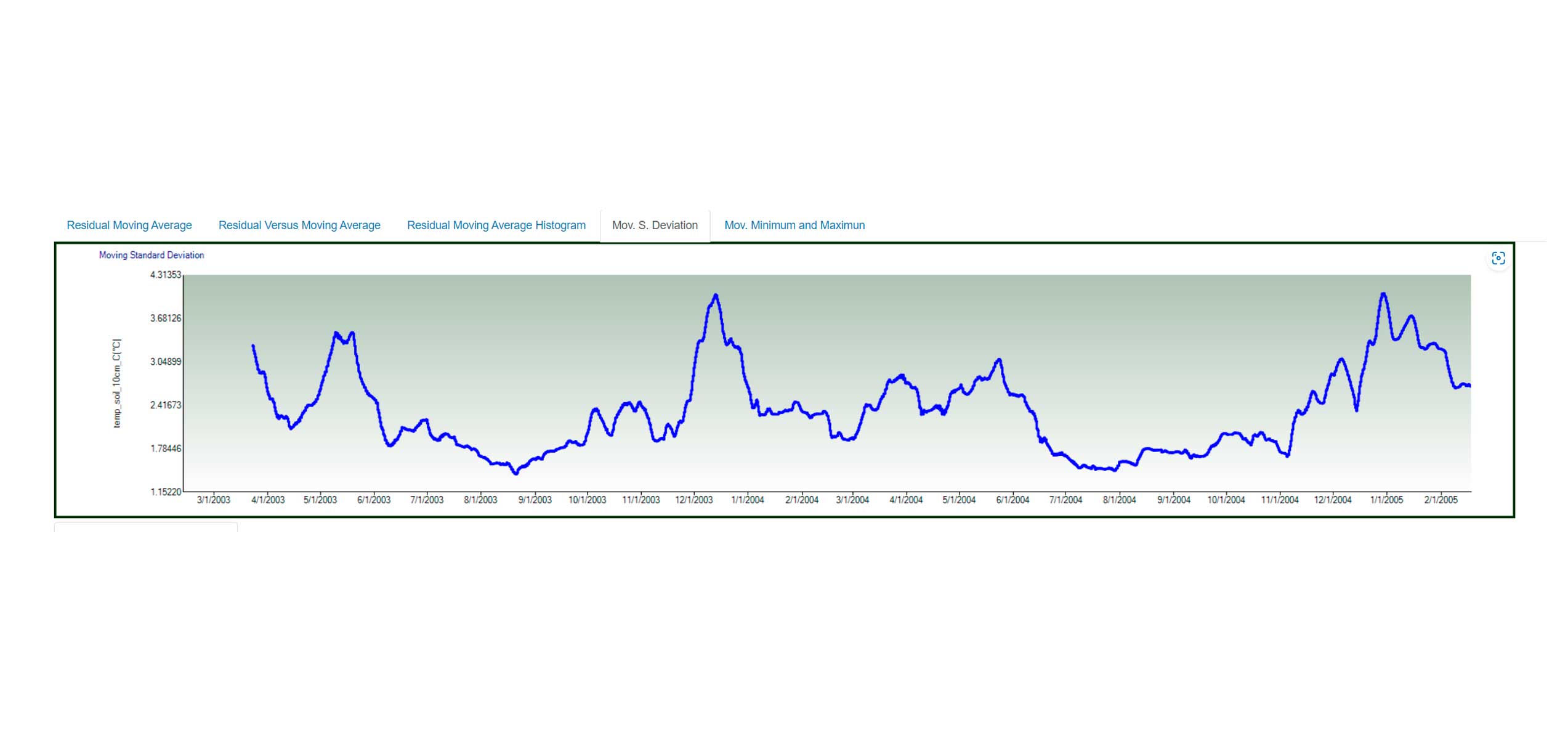
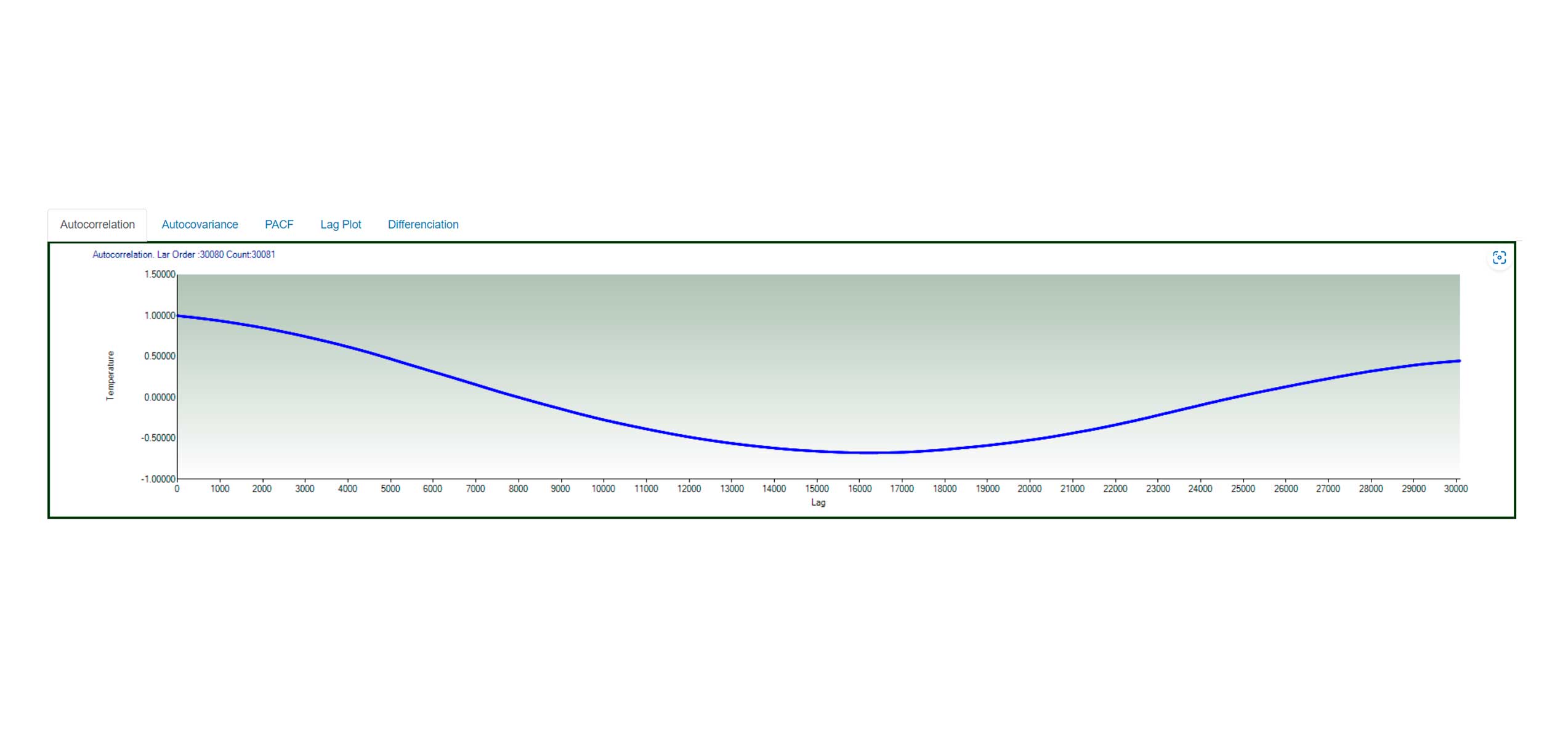
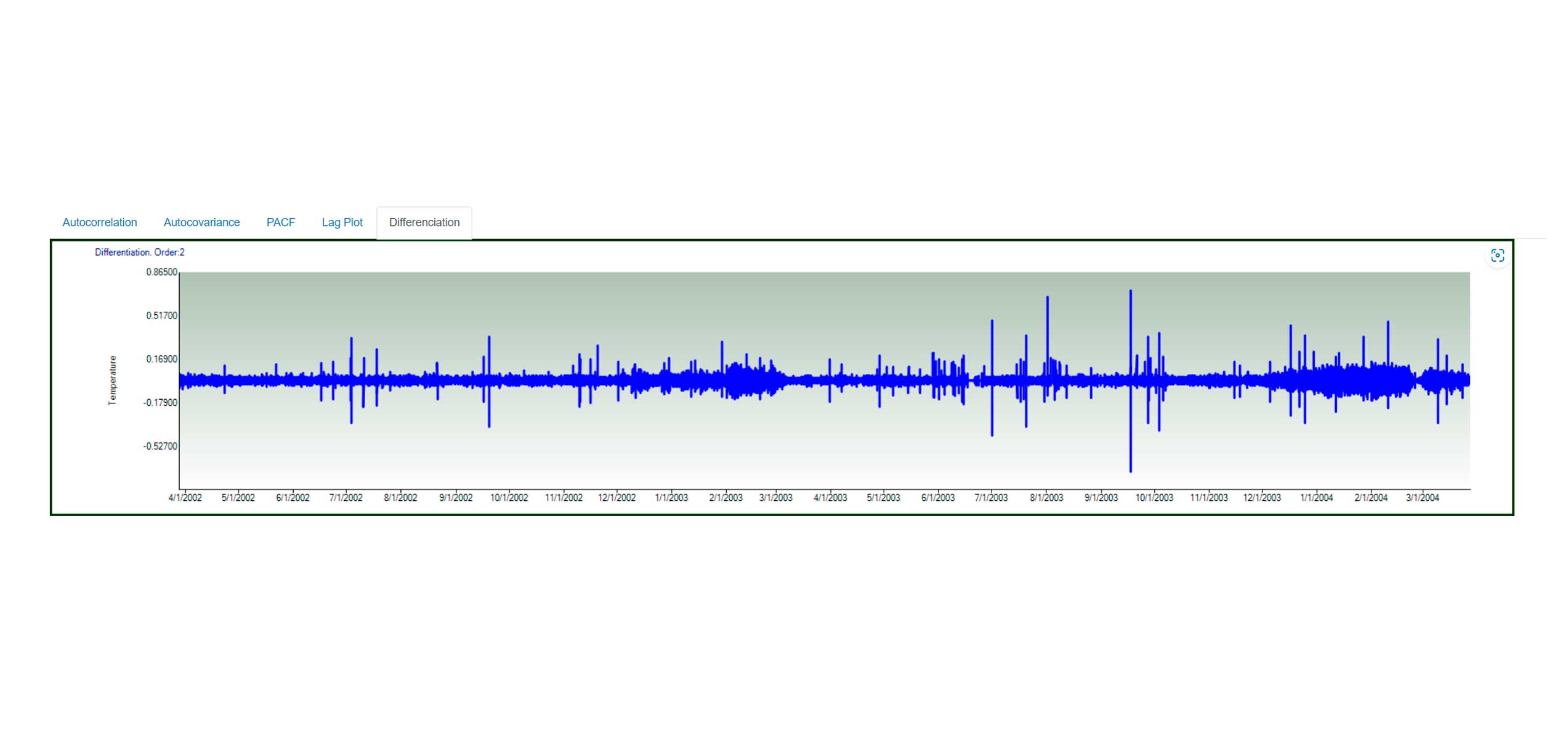
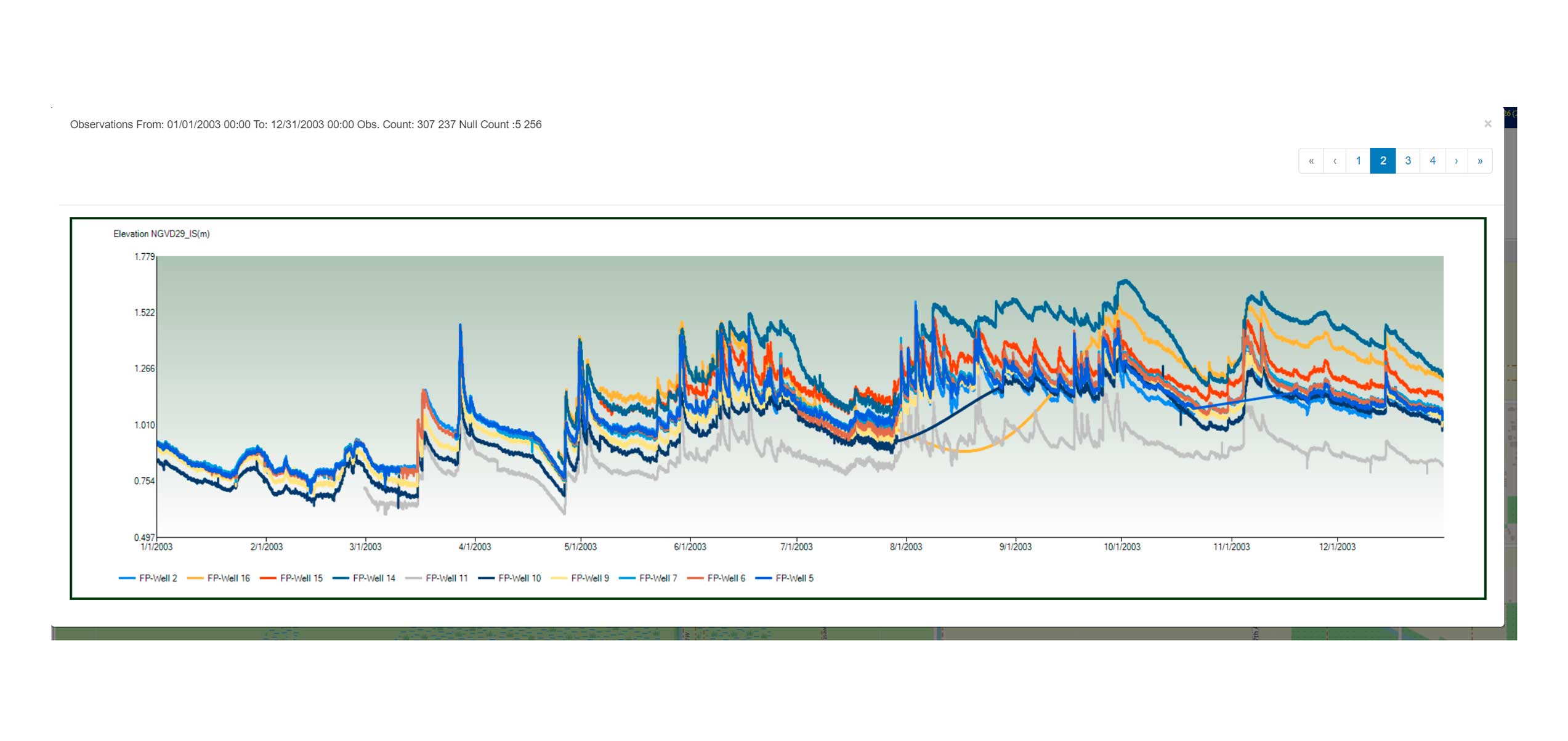
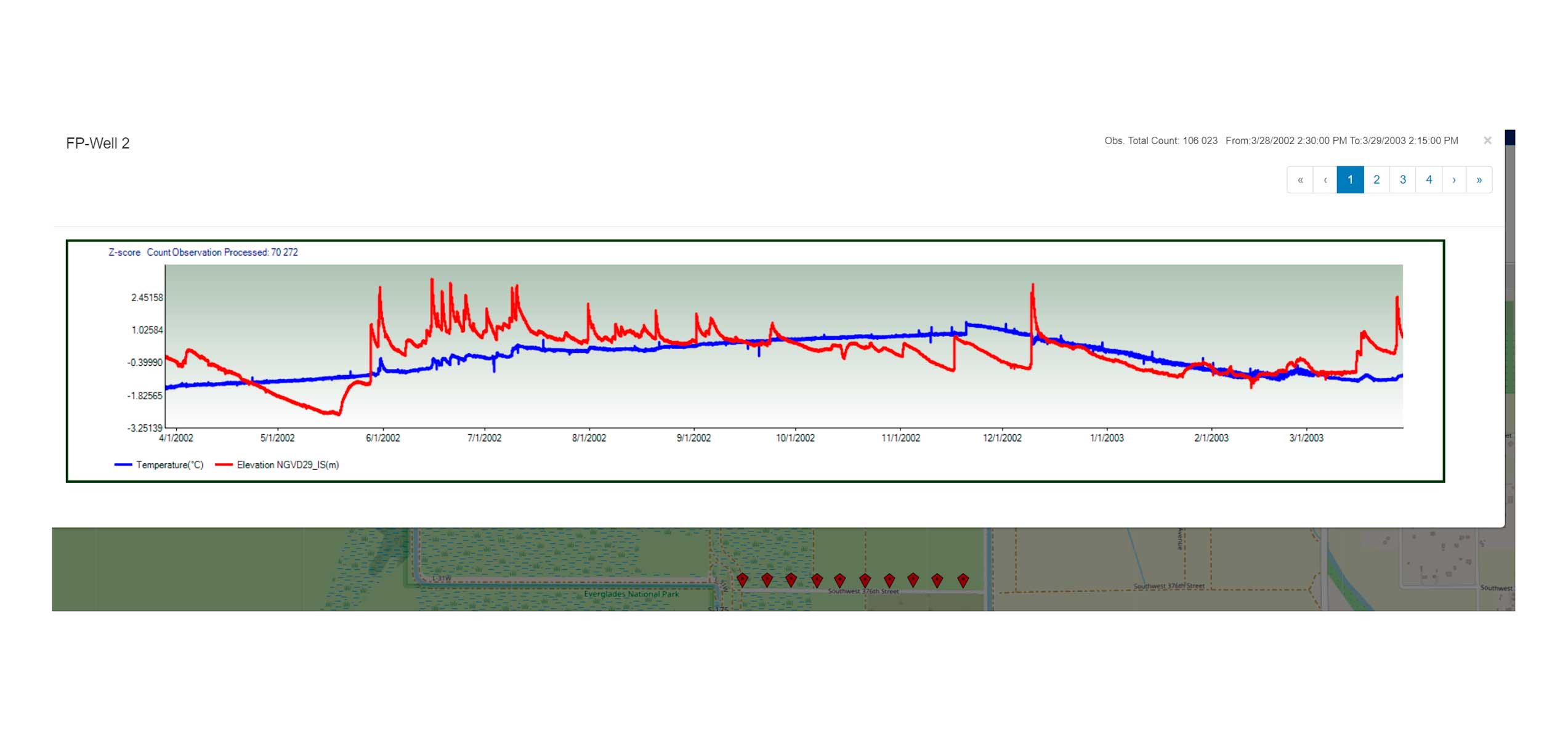
Variable Comparison
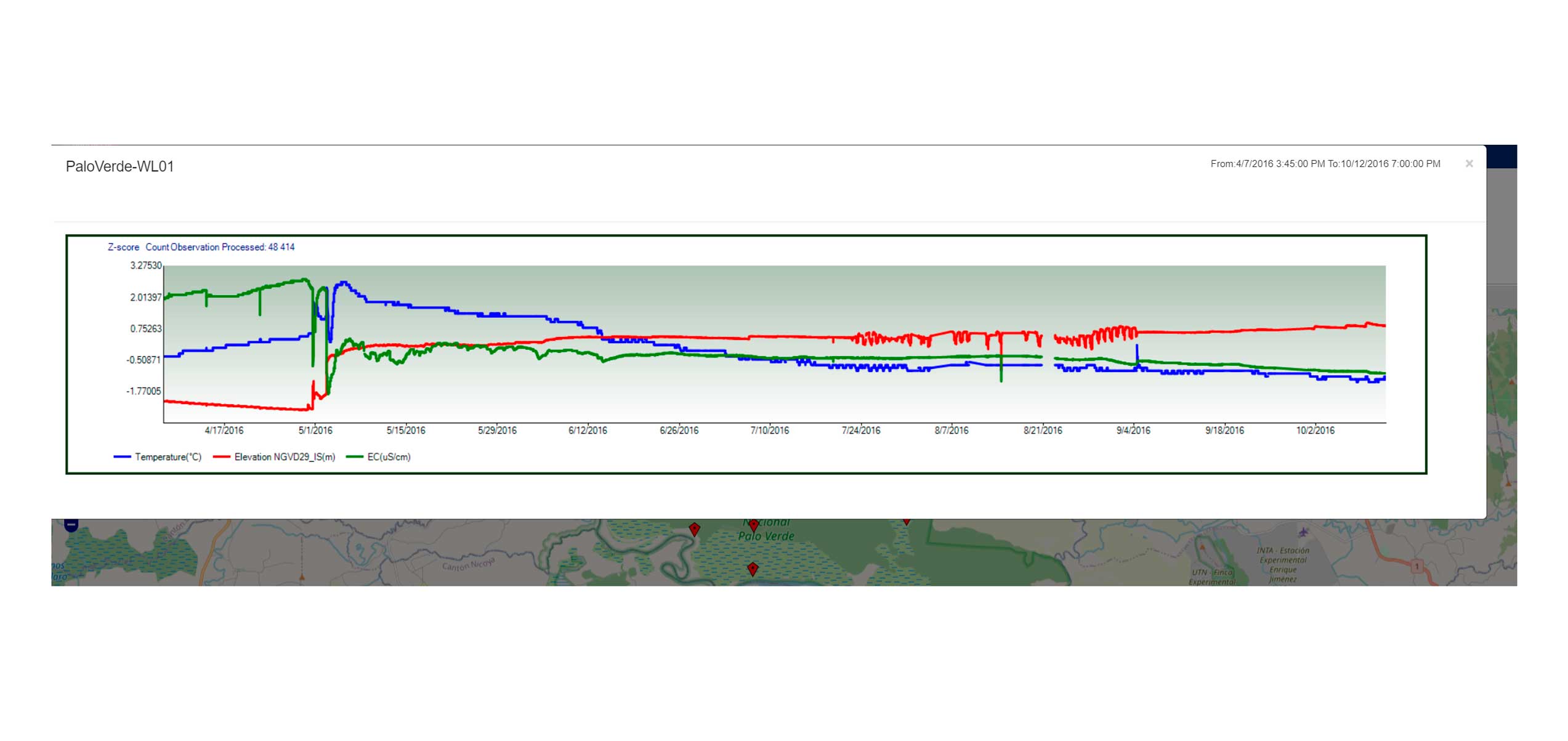
Data Curation
Resources, Data Analytics, Extensible Framework
Rich repository of solutions can be created and shared.
Centralized Machine Learning processing. Experts focus on modeling. Final user can easily process long running tasks in background.
Regardless who designed a processing job, new processing versions can be redefined.
Final users enrich and extend processing capabilities
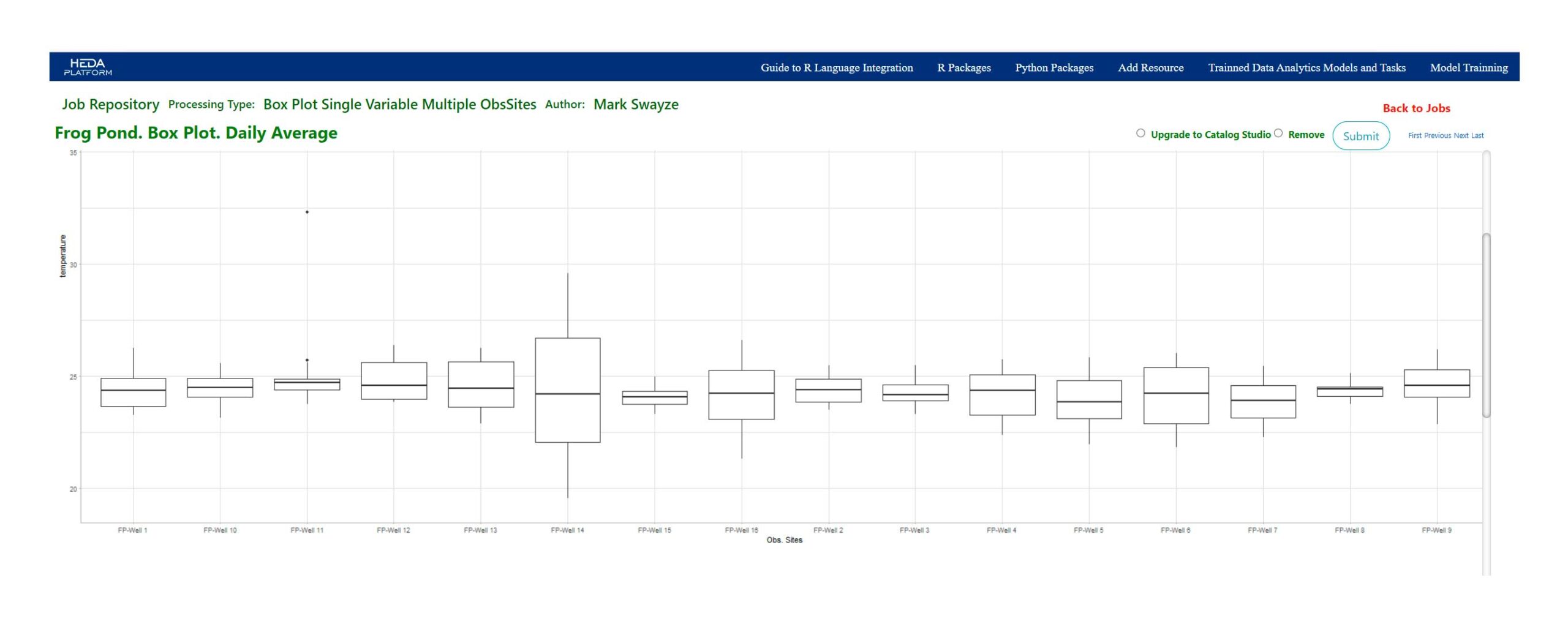
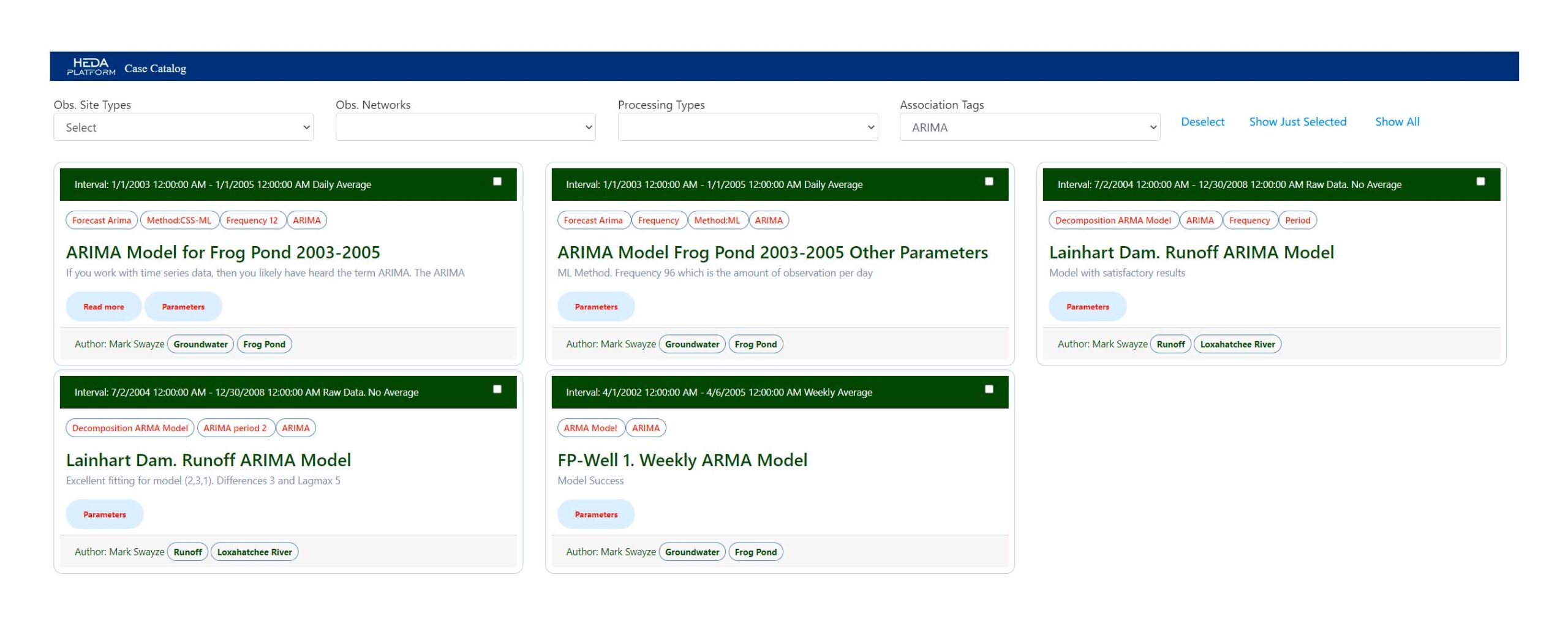
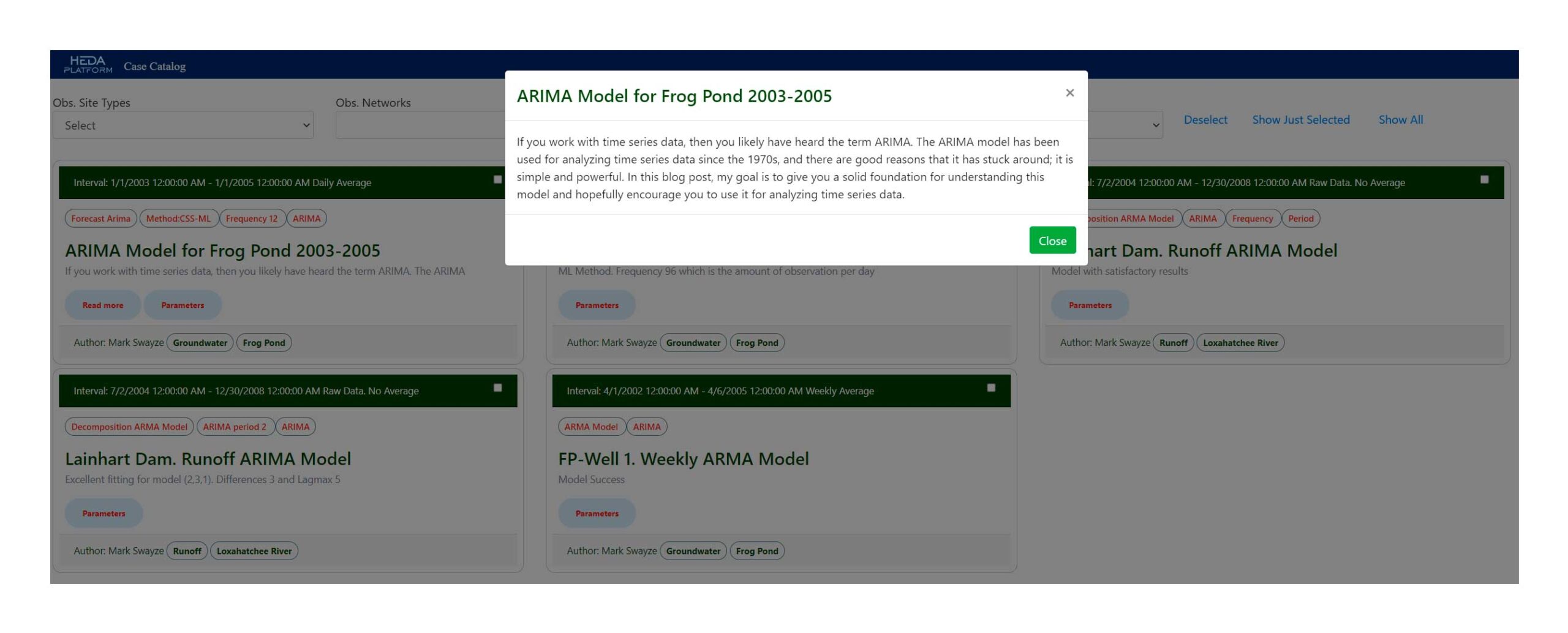
Definitions
Job Authoring allows Final Users to make use of all available resources in the hydroEDA Platform.
Resources are R Language and Python scripts as well as built-in processing resources.
R Language and Python scripts have been added to hydroEDA Platform by the Final User Community.
Job Authoring is defined as a resource selection and selection of Observation Sites/Variables to the processing the resource offers.
The selection of Observation Sites/Variables implies also, the definition of a Time Interval upon which the processing is to take place.
For the chosen Time Interval, the processing could be for the whole Interval or for Patitions of that Interval.
Data under processing, could be Raw Data as stored in HydroEda or data could be summarized by Days, Weeks, Months, Quarter and Year.
Job Authoring Characteristics
Final Users select a processing resource and apply such a processing to Observation Sites/Variables/Interval.
The Observation Sites/Variables/Interval selected for the Job must be compliant with Resource processing characteristics.
For instance:
If a Resource accepts just non null values, the selected Observation Sites/Variables/Interval must follow such a constraint.
If a Resource demands multiple Observation Sites and multiple Variables, the corresponding selection must contain multiple Observation Sites and Multiple Variables.
Every resource has Operation Characteristics which guides Final Users to the Job specification.
A Job is run "Out of Band", it means, Final Users should invoke its processing in the Gateway Data Analytics Service.
Every Job Name must be unique in the system.
Job processing is Success or Failure. Job Author must analyze Failure cause and delete the Job.
Successful Jobs go through a Cuaration process in the Gateway Data Analytics Service.
Job Authoring Guide for mregy
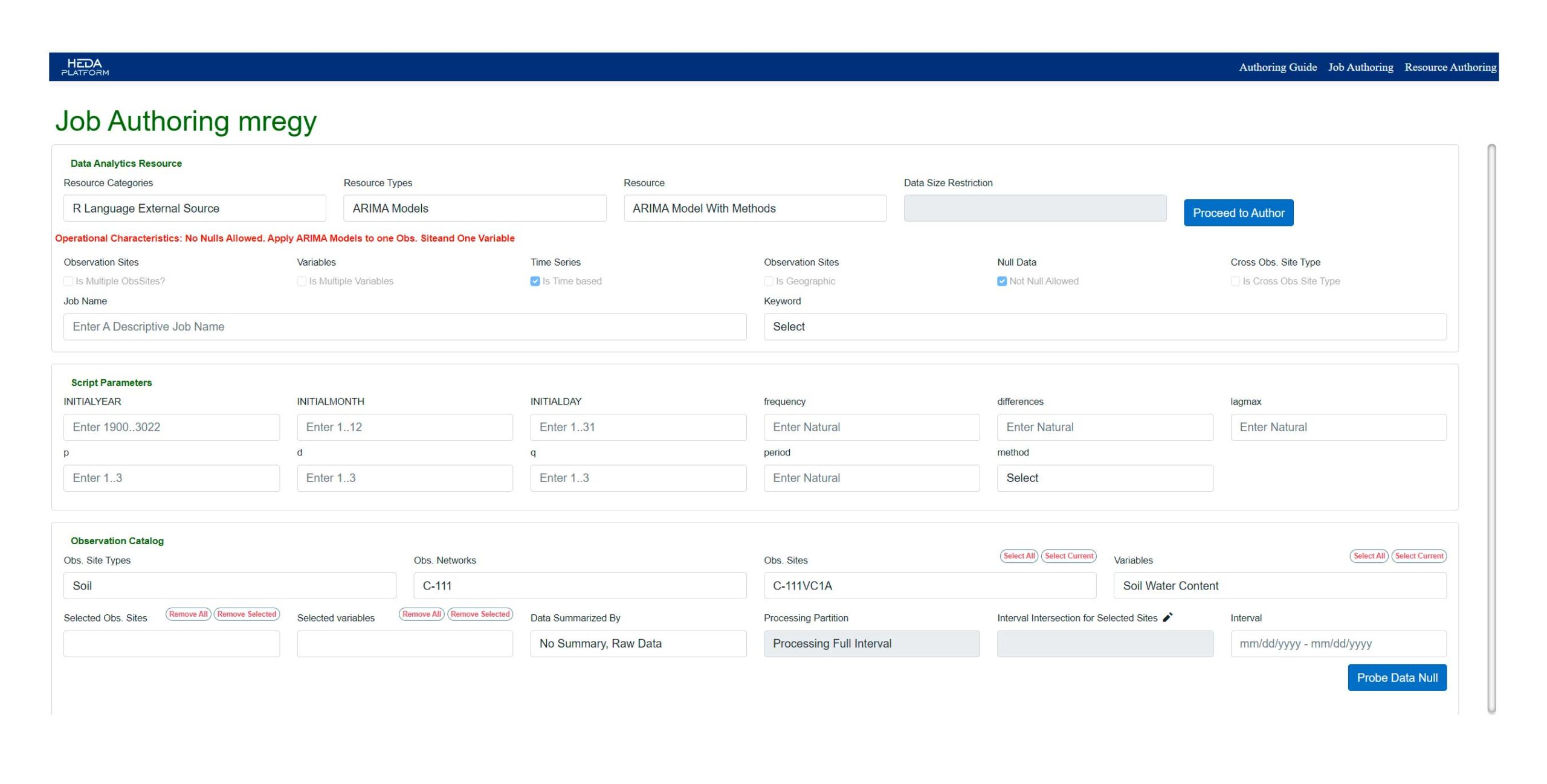
Register and start:
Enhancing hydrological research
Creating presentations and documents
Teaching hydrology with R and Python
NEW FUNTIONALITIES
COMING SOON
Isolines Maps & Content Creation
Data Correction. Interpolation integrated with Data Removal
Better User Experience in Data Correction
New Capabilities in Dashboard for Interval Selection
API Documentation
Interaction with R Language
Interaction with R Language for Data Curation Purposes
CUAHSI-HIS Integration
Variable Zonalization via Cluster Analysis
The hydroEDA main entities
Observation Networks
Observation Site Type
Observation Sites
Relationship
- HEDA works with quantitative information defined as variables registered by sensors and field stations. Sensors and field stations are named Observation Sites
- Observation Sites are located in areas under endeavour. Areas under study are named Observation Networks
- Variables are catalogued and categorized according to types. The variable categories are named Observation Categories
- An Observation Network contains Observation Sites which measure Variables of different Observation Categories
hydroEDA details
- Remarkable Performance in Relational Database Arena.
- Timeliness Accessibility and Integrity.
- Rich searching and drilldown capabilities.
- Inferential Statistics.
- Hypothesis Testing.
- Measure of Association.
- Homogeneity of the Variance.
- Analysis of the Variance.
- Parametric and Non-Parametric Tests.
- Frecuency Histogram
- Box Plot
- Normal Probability Plot
- Goodness-of-fit tests
- Lag Plot
- Scatter Plot
- Regression Curve
- Data Filtering By Value
- Data Filtering By Range
- Outlier detection and removal
- On-line Editing and Reconciliation of Data
- Simple Average
- Exponential
- Triangular
- Weighted
- Fast Fouries
- Transformation
- Power Spectrum
- Wavelet
- ARMA
- ARIMA
- Regression
- ANOVA Regression
- Deterministic Models
- Residual Analysis
hydroEDA Platform type of users
Observation Network Owner
Publisher
Final User
Are able of adding Observation Networks and govern the Data Curation capabilities
Participate with Observation Network Owner in the management of Observation Networks and its content
Is a passive user who access the intrinsic functionalities of the system and the content generated by Observation Network Owner and Publisher
Users are classified into Roles
User can have different Roles in different Observation Networks
An Observation Network could have more than one Observation Owner
hydroEDA Platform architecture and fuctionalities
hydroEDA Platform is a suite of Microservices with a Web-based front end and offers intrinsic funtionalities plus users can add, without limits, R Language and Python solutions.
hydroEDA Platform services allow users to create different Contents with specific objectives as well as Import, Export, Curate data, Create Customs Variables, and much more functionalities.
- Resources can be built with external scripts and packages.
- Data Analytics’s ecosystem enables growth and scale of operation and innovation through composing resources
- Building small and independent resources lowers members’s cognitive load
- Users can use open-source packages and frameworks for predictive analytics and machine learning.
- The scripts are executed inside hydroEDA Platform eco system without moving data outside or over the network.
- Provide an interface between hydroEDA Platform and data science languages such as R and Python.
- The goal is to reduce friction when moving data science solutions into production, and protecting data exposed during the development process.
- By executing a trusted scripting language within a secure framework managed by hydroEDA Platform, data owners can maintain security while allowing data scientists access to enterprise data.
- Provide an interface between hydroEDA Platform and data science languages such as R and Python.
- The goal is to reduce friction when moving data science solutions into production, and protecting data exposed during the development process.
- By executing a trusted scripting language within a secure framework managed by hydroEDA Platform, data owners can maintain security while allowing data scientists access to enterprise data.
- Resources can be built with external scripts and packages.
- Data Analytics’s ecosystem enables growth and scale of operation and innovation through composing resources
- Building small and independent resources lowers members’s cognitive load
- Users can use open-source packages and frameworks for predictive analytics and machine learning.
- The scripts are executed inside hydroEDA Platform eco system without moving data outside or over the network.
- Provide an interface between hydroEDA Platform and data science languages such as R and Python.
- The goal is to reduce friction when moving data science solutions into production, and protecting data exposed during the development process.
- By executing a trusted scripting language within a secure framework managed by hydroEDA Platform, data owners can maintain security while allowing data scientists access to enterprise data.
- Provide an interface between hydroEDA Platform and data science languages such as R and Python.
- The goal is to reduce friction when moving data science solutions into production, and protecting data exposed during the development process.
- By executing a trusted scripting language within a secure framework managed by hydroEDA Platform, data owners can maintain security while allowing data scientists access to enterprise data.

- Resources can be built with external scripts and tested processing units
- Data Analytics’s ecosystem enables growth and scale of operation
- Resources has independent life cycle
- Data Analytics Services ecosystem enables innovation through composing resources
- Autonomous teams responsible for Resources
- Building small and independent resources lowers Team Member’s’ cognitive load
- Centralized Machine Learning processing. Experts focus on modeling. Final user can easily process long running tasks in background.
- Regardless who designed a processing job, new processing versions can be redefined.
- Rich repository of solutions can be created and shared.
- Users can use open-source packages and frameworks for predictive analytics and machine learning.
- The scripts are executed inside hydroEDA Platform eco system without moving data outside or over the network.
- The purpose of the extensibility framework is to provide an interface between hydroEDA Platform and data science languages such as R and Python.
- The goal is to reduce friction when moving data science solutions into production, and protecting data exposed during the development process.
- By executing a trusted scripting language within a secure framework managed by hydroEDA Platform, data owners can maintain security while allowing data scientists access to enterprise data.
hydroEDA Platform architecture and fuctionalities
HydroEDA Portal is a suite of Microservices with a Web-based front end and offers intrinsic funtionalities plus users can add, without limits, R Language and Python solutions.
HydroEDA Portal services allow users to create different Contents with specific objectives as well as Import, Export, Curate data, Create Customs Variables, and much more functionalities.
- Resources can be built with external scripts and packages.
- Data Analytics’s ecosystem enables growth and scale of operation and innovation through composing resources
- Building small and independent resources lowers members’s cognitive load
- Users can use open-source packages and frameworks for predictive analytics and machine learning.
- The scripts are executed inside hydroEDA Platform eco system without moving data outside or over the network.
- Provide an interface between hydroEDA Platform and data science languages such as R and Python.
- The goal is to reduce friction when moving data science solutions into production, and protecting data exposed during the development process.
- By executing a trusted scripting language within a secure framework managed by hydroEDA Platform, data owners can maintain security while allowing data scientists access to enterprise data.
- Provide an interface between hydroEDA Platform and data science languages such as R and Python.
- The goal is to reduce friction when moving data science solutions into production, and protecting data exposed during the development process.
- By executing a trusted scripting language within a secure framework managed by hydroEDA Platform, data owners can maintain security while allowing data scientists access to enterprise data.
- Resources can be built with external scripts and packages.
- Data Analytics’s ecosystem enables growth and scale of operation and innovation through composing resources
- Building small and independent resources lowers members’s cognitive load
- Users can use open-source packages and frameworks for predictive analytics and machine learning.
- The scripts are executed inside hydroEDA Platform eco system without moving data outside or over the network.
- Provide an interface between hydroEDA Platform and data science languages such as R and Python.
- The goal is to reduce friction when moving data science solutions into production, and protecting data exposed during the development process.
- By executing a trusted scripting language within a secure framework managed by hydroEDA Platform, data owners can maintain security while allowing data scientists access to enterprise data.
- Provide an interface between hydroEDA Platform and data science languages such as R and Python.
- The goal is to reduce friction when moving data science solutions into production, and protecting data exposed during the development process.
- By executing a trusted scripting language within a secure framework managed by hydroEDA Platform, data owners can maintain security while allowing data scientists access to enterprise data.
- Resources can be built with external scripts and tested processing units
- Data Analytics’s ecosystem enables growth and scale of operation
- Resources has independent life cycle
- Data Analytics Services ecosystem enables innovation through composing resources
- Autonomous teams responsible for Resources
- Building small and independent resources lowers Team Member’s’ cognitive load
- Centralized Machine Learning processing. Experts focus on modeling. Final user can easily process long running tasks in background.
- Regardless who designed a processing job, new processing versions can be redefined.
- Rich repository of solutions can be created and shared.
- Users can use open-source packages and frameworks for predictive analytics and machine learning.
- The scripts are executed inside hydroEDA Platform eco system without moving data outside or over the network.
- The purpose of the extensibility framework is to provide an interface between hydroEDA Platform and data science languages such as R and Python.
- The goal is to reduce friction when moving data science solutions into production, and protecting data exposed during the development process.
- By executing a trusted scripting language within a secure framework managed by hydroEDA Platform, data owners can maintain security while allowing data scientists access to enterprise data.
- Centralized Machine Learning processing. Experts focus on modeling. Final user can easily process long running tasks in background.
- Regardless who designed a processing job, new processing versions can be redefined.
- Rich repository of solutions can be created and shared.